
L'essentiel
- Marc
- ALPHANET
- Professionnel
- Politique
- Conseil communal de Cernier
- Entente communale de Cernier
- linux-neuchâtel
Documentations de Marc
- Introduction
- Documents
- Sources
- Définitions
- Recommandations de système et plateforme standard
- Installation standard
- Partitionnement standard
- Configuration d'interface réseau sur système d'exploitation standard
- Accès à un serveur standard dans un réseau interne par tunnel SSH inverse
- Installation d'un tunnel SSH sur petit routeur ADSL
- Debugging réseau
- Debugging d'applications
- Récupération d'un système en cas de problèmes
- Lorsque le système ne démarre plus / ne démarre pas correctement / en cas de perte du mot de passe root
- Duplication d'un système
- Lorsque un système de fichiers ne peut être réparé
- Lorsque la table des partitions a été perdue
- Restauration correcte de données sauvegardées via tar
- Solution intégrée: DR
- Ce que vous pouvez faire à l'avance
- Comparaison de données
- Sauvegardes
- Repartitionnement
- Cache disque ou pas ?
- Performance-tuning d'un système standard
- Introduction
- Identification du problème
- Correction de paramètres
- Surveillance des effets
- Mémoire virtuelle
- Espace privé (adressage) de chaque processus
- Localisation et types de zones
- Swapping et paging
- Taille idéale
- Type de zones de swap
- Sécurité
- Différence entre mémoire allouée par malloc(3) ou brk(2) et mémoire accédée effectivement
- Comportement d'allocation réel
- Exemple pratique en C et discussion
- The OOM Killer
- Les motivations de l'overcommit et les améliorations possibles
- Bon dimensionnement de la RAM
- En pratique
- Redimensionnement d'un volume logique LVM
- Synchronisation de données
- Types de machines virtuelles
- Compatibilité matérielle
- Mise en garde
- Administratif
Introduction
Ceci est un essai de publication de documents avec TWiki. Le but final est de migrer les documentations publiques de RTFM ici, puis d'éventuellement référencer, voire intégrer, ces documents de base dans des cours. Un peu de pub parasite CRIL, faut-il déplacer cela dans une homepage professionnelle? dans CRIL ? split? éviter les redites avec Wikipedia?
Documents
Sources
Ces documents sont désormais maintenus dans mon TWiki. Les sources sont multiples (mes mails sur gull, des mails à des clients, des NOTES ou des documentations, des cours, etc). Les droits sont probablement en licence libre, GPL ou GFDL ou assimilé; attribution bienvenue (contactez-moi pour des précisions).Le but serait d'utiliser cette information de manière à éviter les redites (FAQ) ou les duplications (cours).
Définitions
Ces documents utilisent fréquemment des termes qui sont définis ici:
| standard | Ce terme signifie qu'il s'agit d'un système, d'un logiciel, d'un protocole ou d'un procédé qui est recommandé |
Recommandations de système et plateforme standard
- Système d'exploitation
- Debian GNU/Linux stable et à jour (voire Ubuntu LTS (desktop))
- avec éventuellement une liste contrôlée de packages non officiels
- de préférence avec les packages standard CRIL
deb http://packages.cril.ch/cril/debian/packages/ sarge cril
- Plateforme: ix86 (32 bits)
- système de fichiers: ext3 (exception: ext2 pour /boot)
- jeu de caractère: ISO-8859-1
- de préférence (
/etc/environment)LANG=C LC_CTYPE=fr_CH.ISO-8859-1 LC_COLLATE=fr_CH.ISO-8859-1
- de préférence (
Installation standard
De préférence, les systèmes seront installés par FAI via des règles CRIL. Cela préinstalle toute sortes de choses véritablement importantes comme de la surveillance, etc.La mise en place de RAID1 ou de LVM est faite via le test standard de réinstallation automatisé DR CRIL (en même temps que le test obligatoire d'intégrité de reconstruction RAID1).
Partitionnement standard
De manière à limiter les façons de faire (ce qui simplifie les interventions), ainsi qu'à éviter des problèmes, on a standardisé le partitionnement recommandé:
| nom | contenu | cas démarrage RAID1 |
|---|---|---|
| /dev/hda1 | /boot | /dev/md0 |
| /dev/hda2 | swap | /dev/md1 |
| /dev/hda3 | / | /dev/md2 |
D'autres partitions peuvent exister: p.ex. une grande /dev/hda4 comme LVM, dans laquelle sont définis des volumes
logiques pour les données (/data) et la zone non sauvegardée (/scratch), ou une grande partition RAID1 pour
un filesystem ou un LVM.
Il faut savoir que les CD d'installation standard peuvent nommer les périphériques différemment. Par exemple,
/dev/hda peut être /dev/ide/host0/bus0/target0/lun0/disc et /dev/hda1 alors
/dev/ide/host0/bus0/target0/lun0/part1. Le plus simple est d'utiliser la fonction de completion du shell (touche TAB).
Le CD standard DR CRIL n'a pas ce problème, le nommage est cohérent avec le standard ci-dessus.
En SCSI, le même principe de partitionnement est maintenu.
Configuration d'interface réseau sur système d'exploitation standard
Introduction
La configuration d'une interface réseau sur un système d'exploitation standard suppose en général l'utilisation de la suite de protocoles TCP/IP (version 4) et donc, automatiquement des concepts suivants:
| interface réseau | dispositif matériel (p.ex. carte PCI, carte insérable PCMCIA, chip intégré sur une carte-mère: carte Ethernet, WLAN/WIFI (802.11)) ou logiciel (interface loopback virtuelle liant cet ordinateur à lui-même, VPN ou tunnels, liaisons via modem ou port série, etc. Ces interfaces sont nommées suivant le systèmes d'exploitation, par exemple eth0, wlan0, lo, tun0 et ppp0 |
| adresse IP | adresse unique d'une interface sur Internet, ou, dans le cas d'utilisation d'adresses privées (p.ex. dans la plage 192.168.0.0/16 ou d'autres plages sous 172 et sous 10) unique dans le réseau administratif considéré. Ces adresses sont toujours allouées dans le sous-réseau concerné. Elles sont soit configurées manuellement, soit attribuées automatiquement par un serveur DHCP. Dans ce cas, elles sont soit dynamiques (dans une plage d'adresses dédiée), soit assignées statiquement par une table de correspondance mettant en jeu l'adresse MAC de la carte physique. |
| adresse MAC | Adresse définie par le fabricant de la carte physique d'accès au réseau, qui peut servir à assigner des adresses IP de manière fixe, ou à filtrer -- de manière relativement peu sûre -- l'accès à un réseau (p.ex. WLAN/WIFI) |
| routeur par défaut ou passerelle | routeur, sur un sous-réseau TCP/IP, qui sait acheminer les datagrammes plus loin dans le réseau (hors du sous-réseau),: on parle aussi de gateway |
| sous-réseau | découpage logique d'un réseau en plages d'adresses définies par un masque de bits (subnet) |
| netmask | masque de sous-réseau: définit la grandeur de la plage de sous-réseau considérée |
| broadcast | diffusion: définit l'adresse à utiliser pour l'envoi d'un datagramme à toutes les interfaces d'un sous-réseau |
@@A définir plus précisément, car ces concepts sont centraux: interface, ordinateur (un ordinateur peut avoir plusieurs interfaces, de réseaux physiques identiques ou incompatibles, de réseaux logiques souvent différents), ainsi qu'un exemple de calcul de netmask et de présentation d'adresse CIDR, et la précision sur les divers sous-réseaux d'adresses privées. A mon avis des liens à Wikipedia peuvent suffire.
Configuration automatique (DHCP) ou manuelle; adresse dynamique ou fixe; exemple de sous-réseau
La configuration d'une interface peut être automatique (DHCP, attribuée par un serveur: de manière dynamique ou toujours la même adresse, suivant l'adresse MAC de la carte) ou manuelle (configuration de chaque poste et de chaque serveur manuellement). Dans le cas le plus simple, on retrouvera une machine avec une adresse fixe (p.ex. 192.168.1.1, adresse privée valable en interne uniquement), qui attribuera automatiquement et dynamiquement une adresse à chaque équipement dans une plage définie (p.ex. 192.168.1.100 à 192.168.1.199). Certains équipements peuvent malgré tout disposer d'adresses préconfigurées manuellement (fixes): serveurs d'impression, routeurs, firewalls, serveurs. Ces adresses préconfigurées doivent soit figurer en dehors de la plage automatique, ou alors attribuées de manière fixe via une table de correspondance (adresse MAC, adresse IP) par le même serveur DHCP.
- Faire un petit schéma
- montrer une configuration d'un client (/etc/network/interfaces)
- montrer un exemple de configuration via dhclient et/ou pump, pour une fois (scénario visite d'un client)
- parler de la possibilité d'avoir plusieurs configuration statiques ou dynamiques activables
Niveaux de configuration en manuel
Comme on l'a déjà vu précédemment, la configuration peut être automatique (via un serveur DHCP) ou manuelle. C'est ce dernier cas qui nous intéressera ici. Il y a plusieurs façon de le faire:
- temporairement, via la commande ifconfig
- de façon permanente, via le fichier de configuration /etc/network/interfaces
- idem, via un GUI de configuration.
Astuces et recommandations
- Configurez l'ensemble d'un réseau client en adresses privées (p.ex. 192.168.x.y), même les serveurs, même si vous disposez d'assez d'adresses externes. Utilisez les possibilités de translation d'adresse (NAT, voire PAT) de votre routeur/firewall en liaison avec Internet. Vous éviterez ainsi des problèmes sérieux de reconfiguration lorsque vous changerez de fournisseur Internet, p.ex.
- Dans certains cas, tous les équipements (imprimantes, serveurs, clients, etc) devraient être aussi en DHCP (automatique): les adresses attribuées devraient être cependant fixes. Faites-le à l'aide d'une table de correspondance (adresse MAC, adresse IP) dans le serveur DHCP. Cela simplifiera le changement d'adresse, ou le changement de rôles de serveurs. Si vous ne désirez pas le faire, rappelez-vous que la plage dynamique DHCP doit alors être disjointe de la plage fixe (serveurs, etc), comme nous avons vu dans l'exemple précédent.
- Vous vous déplacez fréquemment de client à client. Certaines configuration sont dynamiques, d'autres statiques. Même si le plus simple serait malgré tout de tout mettre en dynamique chez chaque client, vous ne pouvez le faire. @@@ mention de l'outil @@@
- Attention, les routeurs embarqués les plus simples ne supportent pas toutes les fonctionnalités mentionnées ici (NAT, PAT, DHCP statique basé sur MAC, plages d'adresses, etc). La solution la plus flexible est un routeur PC simple (peu de performance) sous GNU/Linux avec netfilter (iptables, kernel V2.4). CRIL fournit une solution intégrée (MLS firewall) sur CD et floppy (sans disque, gage de sécurité et de fiabilité) pour les fonctions de base de firewall, NAT/PAT et DHCP dynamique.
- Assurez-vous que le firmware des équipements firewall soit à jour, respectivement que votre routeur GNU/Linux soit maintenu à jour.
Accès à un serveur standard dans un réseau interne par tunnel SSH inverse
Motivation
Souvent, on met en place un seul serveur standard dans un réseau non standard. Se pose alors la question de l'accès en maintenance distante à ce serveur. A part la mise en place d'un modem direct, ou de redirections de ports (voir tunnel SSH sur petit routeur ADSL), ce qui nécessite souvent la collaboration du département informatique, il est possible de passer outre (en pesant le pour et le contre avec le client final!), ce qui gagne beaucoup de temps.
Introduction
L'idée de cette procédure est de me permettre d'accéder facilement à votre machine depuis l'extérieur. Cette procédure suppose que la machine concernée a un accès Internet complet. Elle fonctionne même si votre machine se trouve derrière un firewall, tant que celui-ici autorise votre machine à sortir via une connexion sécurisée SSH (port 22).Nous allons tester cela durant cette procédure.
En exécutant cette procédure vous acceptez les conditions générales CRIL. Veuillez vérifier que votre responsable système ou département informatique soit au courant de notre intervention!
Test de faisabilité
Connexions externes
Connectez-vous sur la machine concernée comme utilisateur normal. Tapez la commande suivante:
telnet login.alphanet.ch 22
Vous devriez avoir quelque chose comme suit à l'écran:
Trying login.alphanet.ch... Connected to login.alphanet.ch Escape character is '^]'. SSH-1.99-OpenSSH_3.4p1 Debian 1:3.4p1-1
Si cela fonctionne, il vous est possible de contacter n'importe quel service d'une machine externe (dans ce cas une machine chez moi) depuis les machines internes, ce qui est une bonne chose. Tapez plusieurs fois la touche RETURN pour sortir du programme.
Si cela ne fonctionne pas, installez le package telnet ou netcat, ou passez
directement à la section suivante si vous pensez que le firewall
ne posera pas de problème, en particulier si l'erreur est:
bash: telnet: command not found
Vous pouvez aussi essayer 46.140.72.222 à la place de login.alphanet.ch si vous suspectez un
problème de DNS interne.
Etablissement d'un tunnel
Assurez-vous qu'un serveur SSH local est activé et fonctionne (p.ex. ssh localhost -l user),
avec user un utilisateur existant avec un mot de passe valide.
Ensuite, faites la commande suivante. Elle active la possibilité, uniquement
depuis une de mes machines (login.alphanet.ch), d'accéder via protocole sécurisé SSH à
votre ordinateur. J'aurai besoin d'un compte sur votre machine (p.ex. user ci-dessus)
(utilisateur normal pour commencer, voire root si nécessaire).
ssh -R 2222:localhost:22 callback@login.alphanet.ch
(dès que vous aurez tué ce processus, vous couperez l'accès extérieur
sécurisé de login.alphanet.ch)
Appelez-moi dès que vous avez le prompt mot de passe (Password:), et je vous
l'indiquerai puis procéderai à l'intervention.
Techniquement, la commande ci-dessus autorise la machine login.alphanet.ch à se connecter à votre machine, port 22 (serveur SSH) via la connexion SSH déjà établie (tunnel inverse).
Et en mode graphique?
Une manière simple est la suivante: je me loggue sur votre machine via le tunnel inverse établi ci-dessus depuis login.alphanet.ch, sur le compte schaefer (qui doit être le compte sur lequel
vous avez une session ouverture):
ssh -p 2222 -L 5900:localhost:5900 schaefer@localhost
Je configure l'accès à l'écran de votre machine: export DISPLAY=:0
Je lance ensuite x11vnc -storepasswd, puis x11vnc -usepw
Je peux maintenant me connecter à votre écran: vncviewer localhost:5900.
Si nécessaire, depuis une autre machine que login: ssh -L 5900:localhost:5900 login.alphanet.ch
Ensuite j'efface le mot de passe: rm .vnc/passwd.
Alternatives
Il se peut que le firewall interdise toute connexion autre que pour HTTP (port 80). Si en plus un proxy transparent est configuré, il sera impossible d'utiliser cette méthode. Une alternative peut alors être la mise en place d'un redirecteur TCP utilisant des requêtes HTTP via le proxy (éventuellement via une authentification NTLM ...). La mise en place est complexe, et créera une charge importante sur le proxy. Des voies alternatives (comme passer par le département informatique ...) sont alors recommandées.
Source initiale de ce document
Ce document a été migré deId: acces_distant,v 1.2 2005/01/26 20:38:44 schaefer Exp
Installation d'un tunnel SSH sur petit routeur ADSL
Principes
Le but: pouvoir administrer un système client de manière sécurisée, sans mettre en oeuvre des technologies plus complexes comme un VPN, avec une flexibilité très grande et avec un support de matériel assez important. La sécurité dépendra de deux facteurs: la sécurisation du routeur ADSL (configuration sécurisée, mise à jour régulière du firmware) et de la mise à jour du logiciel sur le serveur standard (surtout pour le daemon SSH, éventuellement aussi les bibliothèques SSL et le kernel: idéalement une mise à jour de tout le système avec redémarrage du daemon SSH, voire de la machine en cas de mise à jour du kernel). L'adresse IP du côté ADSL peut être dynamique: on configurera alors un DNS dyndns.org et la mise à jour automatisée dans le routeur ADSL.Le principe: un seul port TCP (aucun en UDP) du routeur ADSL (qui peut très bien être du matériel embarqué bon marché du commerce) est redirigé sur un serveur standard du réseau interne, via NAT/PAT statique. Sur celui-ci le service SSH est activé (port 22). Idéalement, on s'assurera que seules certaines adresses sont autorisées à accéder au port indiqué (donc adresses statiques). Si l'interdiction n'est pas possible/trop lourde, on peut le faire du côté du serveur standard (moins sûr)
Mise en place du NAT/PAT sur le routeur ADSL
Dans l'exemple, on décide que le port 22 du firewall sera PATé statiquement sur le port 22 de la machine 192.168.1.10, ceci sans aucune restriction (depuis tout Internet, sinon restreignez!)
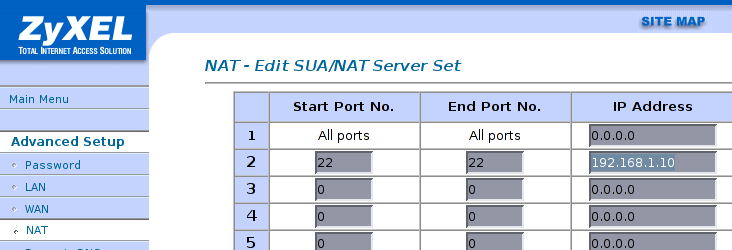
Une alternative serait de choisir un numéro de port externe (du firewall) non connu, ce qui limiterait les logs d'attaque, sans pour autant offrir une véritable sécurité supplémentaire.
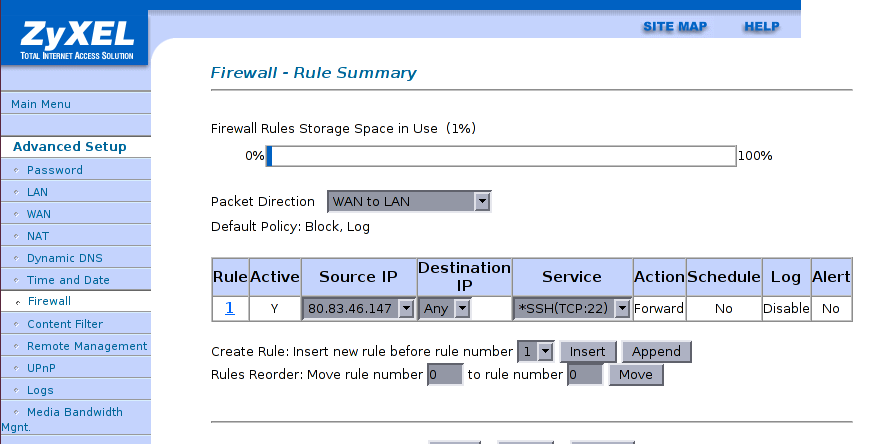
Restriction de port à une adresse IP fixe source
Il est en général une bonne idée de restreindre l'accès à SSH à un certain nombre d'adresse IP statiques, de manière à ne pas avoir une mise à jour critique sur le service SSH en cas de problèmes de sécurité, ou pour diminuer le nombre d'attaques automatisées et donc d'entrées de log.
Mise en place du nom DNS dynamique
Compte chez dyndns.org et ajout d'une entrée DynamicDNS
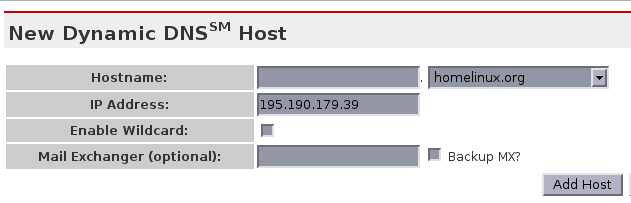
Attention: seul un compte DynDNS gratuit par entité/personne.
Configuration du routeur ADSL
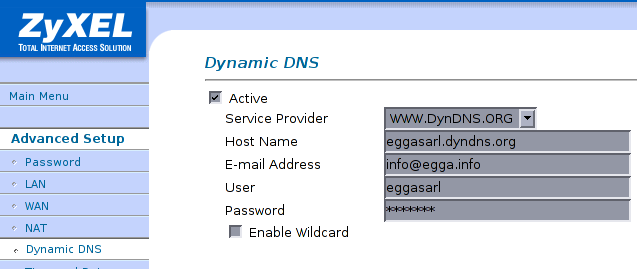
Comme test il est recommandé d'introduire une adresse IP incorrect dans la configuration chez dyndns.org, de tester
qu'elle est incorrecte via p.ex. la commande host, puis de redémarrer le routeur ADSL et de constater que le
DNS change.
Configurations plus complexes et recommandations
Pour des configurations plus complexes, il est recommandé de rediriger tous les ports TCP et UDP sur le serveur standard et de configurer ce dernier comme firewall (deux interfaces réseau au minimum, 3 avec un DMZ) et ne connecter aucun autre équipement sur l'interface externe que le routeur ADSL.Il peut s'agit d'un PC standard, d'un PC embarqué, d'un routeur ADSL sous GNU/Linux, ou d'un MLS firewall (PC bas de gamme sans disque, avec CD-ROM et floppy, sécurisé).
Des VPNs clients peuvent alors être mis en place avec le logiciel multiplateforme OpenVPN?.
Il n'est jamais recommandé de mettre en place les solutions embarquées VPN du commerce (lourdes, complexes, peu sécurisées, problèmes d'interopérabilité) en particulier en IPsec.
Debugging réseau
Le plus simple: l'outil tcpdump
L'avantage est clair: tcpdump s'utilise également sur des systèmes plus simples dépourvus d'interface graphique ou lorsque le fonctionnement ne doit pas nécessairement être interactif.
L'analyse de haut niveau: Ethereal/Wireshark
Utilisation en pratique
Il est bien sûr possible de combiner les avantages des deux outils: capturer tout d'abord sur un système simple distant (p.ex. routeur/firewall) avectcpdump -i eth0 -s 0 -w /tmp/capture -n, puis, sur un système local sous système standard ou non, lancer ethereal /tmp/capture après avoir transféré le fichier, p.ex. avec scp.
Debugging d'applications
Récupération d'un système en cas de problèmes
Lorsque le système ne démarre plus / ne démarre pas correctement / en cas de perte du mot de passe root
Mode recovery
En général, il est possible de sélectionner le démarrage en mode recovery, ce qui est équivalent à la procédure décrite sous mode single user.Mode single user
Le principe est de démarrer en niveauinit single (S) et donc d'éviter beaucoup d'opérations de préparation du
niveau 2 (voir aussi /etc/inittab) et donc de problèmes potentiels.
On active ce mode en ajoutant à la ligne de commande de LILO ou de GRUB le paramètre single. Par exemple,
avec LILO, taper SHIFT au prompt de démarrage, puis TAB pour lister les images. L'image standard s'appelle tout
simplement linux: pour obtenir le mode single user, tapez simplement linux single.
Dans ce mode, les systèmes de fichiers sont en général montés correctement. Par contre, il vous faudra très vraisemblablement le mot de passe root!
En cas de problème, il est possible de spécifier un autre block-device pour /, p.ex. dans le cas standard
linux single root=/dev/hda3 (ou /dev/md2). Ce commentaire est valable pour tous les modes qui suivent.
Si cela ne fonctionne pas, il faut utiliser un mode plus bas niveau, le mode init=/bin/sh.
Mode init=/bin/sh
Le principe est le même que pour le mode single user, sauf que l'on va complètement ignorer les scripts standard d'initialisation du système et lancer directement, dès que le kernel sera chargé (évt. après l'initrd pour les pilotes), un shell root, sans demande de mot de passe!
Le paramètre à ajouter au démarrage est linux init=/bin/sh. Familiarisez-vous au clavier US à l'avance.
Au prompt du shell bash root (#), vous devez commencer par remonter / en lecture-écriture et monter les
autres systèmes de fichiers, si nécessaire
mount / -o remount,rw mount /boot # si vraiment nécessaire: mount -a
Si cela ne fonctionne toujours pas, il faut utiliser un autre média de démarrage.
Utilisation d'un autre média de démarrage et montage des systèmes de fichiers
En général, le partitionnement standard est utilisé, sauf problèmes très particuliers. Seules les partitions/ et /boot sont réellement nécessaires à ce stade.
On se bornera alors à démarrer avec un média de démarrage, par exemple le CD DR CRIL, ou un CD d'installation (aller jusqu'au partitionnement, sans le faire, puis commutez sur la console 2 (ALT-F2) et tapez RETURN pour un shell), puis à faire
mkdir -p /target mount /dev/hda3 /target mount /dev/hda1 /target/boot
Opérations
Une fois le système démarré et les systèmes de fichiers accessibles, on peut modifier (avec les outils du média de
démarrage, ou ceux du système lui-même via chroot /target) p.ex. le fichier /etc/fstab, ou /etc/shadow,
ou lancer la commande passwd, reconfigurer le démarrage, etc
Avant de redémarrer, il faut démonter les systèmes de fichiers. Le cas de / est spécial: si vous l'avez remonté rw, remontez
le ro (read-only).
Reconfiguration du démarrage LILO ou grub
LILO (standard)
Cette méthode peut fonctionner avec le CD d'installation du système, un floppy, un démarrage réseau PXE, ou en déplaçant les disques sur une autre machine.
En supposant LILO, il faut modifier /etc/lilo.conf, changer boot (où l'on stocke le démarrage, souvent /dev/hda p.ex.)
et root (souvent /dev/hda3 ou /dev/md2 en cas de démarrage en RAID1).
Il faut ensuite relancer LILO, p.ex. avec lilo -r /target (version de LILO du média de démarrage) ou chroot /target /sbin/lilo.
Notez que si le système démarre en RAID1, il faut réinstaller deux fois LILO (une fois avec boot=/dev/hda et une fois
avec boot=/dev/hdc si l'on veut un démarrage véritablement RAID1).
Dans tous les cas une adaptation de /etc/fstab peut être nécessaire si les noms ont changé (p.ex. passage de RAID1 à
disque physique, etc).
GRUB (non standard)
Quelque chose comme:
chroot /target # suppose /target/boot aussi monté
grub-install hd0 # si ne fonctionne pas, utiliser ce qui suit
grub
# ceci lance l'interface shell grub
root (hd0,0) # /dev/hda1 p.ex., /boot
setup hd0 # installation dans le MBR
quit
exit # sortir du chroot
# démonter, etc.
Sécurité
Les informations précédentes ont montré qu'on peut passer outre la sécurité d'un système standard. Si cela semble un problème, il faut alors réfléchir aux points suivants:
- peut-on enlever le média de la machine concernée ? (p.ex. le disque système, de données, les sauvegardes, etc)
- peut-on démarrer sur un média amovible (floppy, CD-ROM, SCSI, FC, FW, USB ou réseau?)
- peut-on modifier la configuration du BIOS ?
Si une des questions a une réponse positive, la sécurité du système ne peut être assurée.
On peut résoudre le problème d'une ou plusieurs manières:
- supprimer l'accès physique à la machine (salle fermée à clé)
- mettre un mot de passe (ou deux) sur le BIOS
- s'assurer qu'on ne peut effacer/désactiver cette configuration
- par reset CMOS (cavalier)
- par backdoor
- s'assurer qu'on ne peut effacer/désactiver cette configuration
- empêcher le démarrage sur média amovible (cf sécurisation BIOS ci-dessus)
- ne pas installer de MBR, mais installer LILO ou GRUB directement dans le MBR
- mettre un mot de passe qui empêche la modification des paramètres du kernel ou le démarrage sur d'autres média
- chiffrer les systèmes de fichiers et demander le mot de passe de déchiffrage au démarrage
- matériel de sécurisation (carte de copie et cachage de disque automatique)
Il est clair que faire ainsi augmente le risque de non disponibilité du système (déni de service, DoS?). La réparation ou même le redémarrage de la machine nécessitera une intervention en site. Il s'agit ici d'évaluer les avantages et les inconvénients du niveau de sécurité choisi, sans sombrer dans la paranoïa ni une confiance excessive: les solutions les plus simples sont souvent les meilleures.
Duplication d'un système
La duplication d'un système peut servir pour tests ou correction sur une copie des problèmes (très recommandé dans les cas de problème matériel). Cette duplication peut se faire de diverses manières qui sont détaillées ici.Dans tous les cas, le système dupliqué ne peut pas être utilisé tel quel. Il faut encore adapter au minimum son adresse IP (/etc/network/interfaces) avant de le démarrer. De plus, il se peut qu'il faille reconfigurer le démarrage si le disque est déplacé de bus physique ou pour d'autres raisons.
Duplication brute: dd
=dd=permet de copier byte à byte une partition (p.ex. /dev/hda1) ou un disque entier (p.ex. /dev/hda) sur un autre de taille au moins égale ou dans un fichier, à fins d'analyse ou de travail. L'optionconv=noerror,sync est utile si le disque comporte des erreurs matérielles. Si le mode DMA n'est pas activé
(voir hdparm -v /dev/hda /dev/hdc, puis hdparm -d 1 /dev/hd[ac] si le mode DMA est connu comme fonctionnel),
la copie peut prendre beaucoup de temps. De toute manière la copie prendra plus de temps que via une copie intelligente
(voir plus bas), surtout si le disque n'est pas utilisé sur toute sa capacité.
Par contre, la copie brute permet également de dupliquer des OS non standard très facilement, si nécessaire et légal.
Regénération par copie tar
Le plus simple est de le faire par la solution intégrée DR
Lorsque un système de fichiers ne peut être réparé
L'outil debuge2fs permet de récupérer certaines données, éventuellement. Une autre idée serait d'utiliser p.ex.
dump/restore (jamais essayé).
Lorsque la table des partitions a été perdue
L'utilitaire gpart permet de scanner un disque entier et de retrouver, éventuellement, les partitions et types de filesystems
qu'il contenait.
Restauration correcte de données sauvegardées via tar
Il faut utiliser la commandetar --directory=/target --numeric-owner -xpf FICHIER, en supposant que tous les systèmes de fichiers ont été montés (p.ex. /target, /target/boot, /target/data, /target/scratch, etc; mkdir si nécessaire!) et que le chemin au fichier de sauvegarde est FICHIER.
Ensuite, reconfigurez le démarrage.
Solution intégrée: DR
CRIL fournit une solution intégrée de disaster-recovery avec réinstallation, repartitionnement, recréation des systèmes de fichiers, du swap, des volumes LVM et/ou RAID, etc, depuis de nombreux média, compris dans le forfait d'installation de nouveaux systèmes standards et adaptable, en règle général, à des systèmes standards, voire déviant un peu dans le monde des logiciels libres.
Ce que vous pouvez faire à l'avance
Introduction
Quelques suggestions pour simplifier la reprise en cas de problème:
- imprimer certains fichiers systèmes (
/etc/fstab,/etc/network/interfaces) ainsi que la sortie de certaines commandes commefdisk -l - standardiser le partitionnement
- cette documentation
- maintenir à jour un dossier pour chaque machine avec
- disquette de démarrage
- DR
- CD de démarrage
- floppy de configuration, testé
- partitionnement, etc (feuille imprimée)
- affectation de la machine (p.ex. formulaire CRIL@@@)
- spécialités, cas spéciaux, etc.
- éventuellement une copie des 2 premiers secteurs du disque-dur quelque part (MBR et table des partitions)
- toute modification du matériel ou du kernel devrait faire l'objet de tests poussés
- mémoire (p.ex
memtest86) - I/O (@@@ détailler!)
- mémoire (p.ex
Génération d'un média amovible de démarrage
Si c'est juste le démarrage qui pose problème, p.ex. dans un array RAID avec un BIOS qui ne supporte pas le démarrage sur le 2e disque, on peut utiliser un autre média de démarrage.
Solutions simples
- p.ex. Ubuntu a une fonction démarrer le système installé sur son CD live/install standard
- si le kernel est petit et qu'il n'y a pas d'initrd (rarement le cas aujourd'hui sauf kernel optimisé soi-même!)
cp /boot/vmlinuz /dev/fd0 rdev /dev/fd0 /dev/md2 # si / est /dev/md2
Solutions plus générales
- génération d'un CD-ROM de démarrage compatible avec votre système, avec support initrd
apt-get install simple-scripts syslinux # ce qui suit pas forcément sous root # adapter le chemin de vmlinuz, initrd et le périphérique pour / /usr/lib/simple-scripts/scripts/make-boot-cd /boot/vmlinuz /boot/initrd /dev/hda3 /tmp/cd.iso # graver cd.iso, p.ex. via /usr/lib/simple-scripts/scripts/record_cds.sh, sous root
Comparaison de données
Sauvegardes
Toute sauvegarde devrait être suivie, régulièrement, d'un contrôle d'intégrité des données, voire d'une restauration-test sur un système de test, vérifiée.
Repartitionnement
Introduction
Parfois, le partitionnement initial est mal conçu, et il faut repartitionner. Cela est également valable dans le cas de l'installation d'un système standard alors qu'un système non standard est encore installé.Quelques conseils pour éviter le repartitionnement manuel:
- ne pas trop créer de partitions, en particulier pour un système desktop
- /boot, swap et / sont suffisants (évt. /data pour /data/home, etc, encore)
- mettre en place du LVM s'il s'agit d'un serveur de données
Repartitionnement manuel
Introduction
Le plus simple est avec un CD-ROM Ubuntu live/install 6.06 LTS, sans monter les divers systèmes de fichiers. Il contient déjà la commandeparted
montrée ici.
Partitionnement
root@ubuntu:~# fdisk -l /dev/sda Disk /dev/sda: 120.0 GB, 120060444672 bytes 255 heads, 63 sectors/track, 14596 cylinders Units = cylinders of 16065 * 512 = 8225280 bytes Device Boot Start End Blocks Id System /dev/sda1 * 1 14317 115001271 83 Linux /dev/sda2 14318 14596 2241067+ 5 Extended /dev/sda5 14318 14596 2241036 82 Linux swap / Solaris
Procédure (dans notre cas)
On voit que le plus simple est de:
- supprimer le swap et sa partition étendue qui le contient
- redimensionner /dev/sda1
- recréer le swap
- adapter /etc/fstab du système installé
- réinstaller/reconfigurer le démarrage
Suppression de partitions
root@ubuntu:~# fdisk /dev/sda [ ... ] Command (m for help): d Partition number (1-5): 5 Command (m for help): d Partition number (1-5): 2 Command (m for help): w
évt. revérifier avec fdisk -l /dev/sda, voire redémarrer.
Repartitionnement avec parted
Ensuite repartitionner /dev/sda1:
root@ubuntu:~# parted /dev/sda [ ... ] (parted) p Disk geometry for /dev/sda: 0kB - 120GB Disk label type: msdos Number Start End Size Type File system Flags 1 32kB 118GB 118GB primary ext3 boot (parted) p 1 Minor: 1 Flags: boot File System: ext2 Size: 118GB (98%) Minimum size: 4264MB (4%) Maximum size: 120GB (100%) (parted) resize 1 Start? [32kB]? End? [118GB]? 20GB
L'opération dure un certain temps.
Il est bien de redémarrer, à ce stade, en particulier si une mise en garde a été affichée par fdisk à l'écriture
de la table des partitions.
Vérification
Par acquit de conscience:
root@ubuntu:~# e2fsck -f /dev/sda1 e2fsck 1.38 (30-Jun-2005) Pass 1: Checking inodes, blocks, and sizes Pass 2: Checking directory structure Pass 3: Checking directory connectivity Pass 4: Checking reference counts Pass 5: Checking group summary information /dev/sda1: 87246/2457600 files (0.8% non-contiguous), 666722/4883752 blocks
Création des partitions
Il faut ici:
- (re)-créer la partition étendue /dev/sda2
- (re)-créer la partition de swap /dev/sda5
- créer une nouvelle partition (p.ex. pour installer un autre système) /dev/sda6
root@ubuntu:~# fdisk /dev/sda [ ... ] Command (m for help): n Command action e extended p primary partition (1-4) e Partition number (1-4): 2 First cylinder (2433-14596, default 2433): Using default value 2433 Last cylinder or +size or +sizeM or +sizeK (2433-14596, default 14596): Using default value 14596
Création de la partition de swap (du bon type 0x82):
Command (m for help): n Command action l logical (5 or over) p primary partition (1-4) l First cylinder (2433-14596, default 2433): Using default value 2433 Last cylinder or +size or +sizeM or +sizeK (2433-14596, default 14596): +2G Command (m for help): t Partition number (1-5): 5 Hex code (type L to list codes): 82 Changed system type of partition 5 to 82 (Linux swap / Solaris)
Création de la nouvelle partition:
Command (m for help): n Command action l logical (5 or over) p primary partition (1-4) l First cylinder (2677-14596, default 2677): Using default value 2677 Last cylinder or +size or +sizeM or +sizeK (2677-14596, default 14596): Using default value 14596
Mémorisation
Command (m for help): w
Il est bien de redémarrer, à ce stade, en particulier si une mise en garde a été affichée par fdisk à l'écriture
de la table des partitions.
Création du swap
mkswap /dev/sda5
Reconfiguration de /etc/fstab
Dans notre cas, aucune partition n'ayant changé de numéro, aucun changement n'est donc nécessaire.
La nouvelle partition /dev/sda6 est donc disponible pour travail.
Reconfiguration du démarrage
Dans notre cas, le démarrage étant fait via grub et la partition /
n'ayant pas changé de numéro ou de disque, aucune reconfiguration n'est
nécessaire.
Dans le cas de LILO, il faudrait relancer LILO.
Cache disque ou pas ?
(On parle ici du cache embarqué dans les disques-durs, et non pas du cache automatique Linux utilisant le maximum de mémoire libre).
Le cache disque en lecture ne gêne que rarement. Le cache disque en écriture est gênant pour des raisons de cohérence des données en cas de coupure de courant ou de crash immédiat (panne franche). Il faut le désactiver dans le BIOS et/ou, pour plus de sécurité, dans Linux (hdparm -W 0 /dev/sd[a-z], à chaque démarrage, automatisable via /etc/default/hdparm). En effet, le cache disque en écriture répond simplement "OK" sans faire l'opération immédiatement! Cela peut être catastrophique en cas de panne.
Les disques actuels sont très performants sans cache disque en écriture dans la mesure où le command-queuing est activée. En SCSI, c'est le cas depuis très, très longtemps. En IDE c'est impossible. En SATA, il faut en général passer le chipset en mode AHCI dans le BIOS, puis vérifier que le command queuing est activé (le problème peut aussi être sur certains disques-durs), par exemple:
virtual:~# grep NCQ /var/log/dmesg [ 2.041800] ata1.00: 1953525168 sectors, multi 0: LBA48 NCQ (depth 31/32), AA [ 2.041804] ata4.00: 1953525168 sectors, multi 0: LBA48 NCQ (depth 31/32), AA [ 2.043176] ata2.00: 1953525168 sectors, multi 0: LBA48 NCQ (depth 31/32), AA [ 2.043180] ata3.00: 1953525168 sectors, multi 0: LBA48 NCQ (depth 31/32), AA
Le command queueing permet de lancer plusieurs commandes de lectures et d'écritures simultanées sur un disque-dur. Le contrôleur du disque-dur va alors réorganiser les commandes de la manière la plus efficace et, du point de vue de la performance, cela remplace avantageusement un cache disque et augmente même les performances au-delà.
Si le command-queueing est impossible sur une configuration donnée, il est aussi possible de laisser le cache-disque et d'activer les write barriers, qui devraient permettre de limiter les dégâts, en particulier en présence de journalisation, en cas de panne franche.
Performance-tuning d'un système standard
Introduction
Identification du problème
Collection de données
Outils
- interactifs
- saidar, htop, top, vmstat
- d'interrogation de données collectées: sar.
Analyse
Correction de paramètres
Surveillance des effets
Mémoire virtuelle
Espace privé (adressage) de chaque processus
La mémoire virtuelle est une extension du concept de la RAM. Chaque processus, sous système standard, voit un espace d'adressage qui commence à zéro et finit à une certaine adresse. Dans cet espace sont rendues accessibles des ressources systèmes, comme par exemple des zones de programmes et bibliothèques partagées, de données ou de la mémoire générique. L'espace privé de chaque processus est en théorie l'adresse maximum de la plateforme standard (4 GB i386, bien plus grand pour amd64 (EMT64)). En pratique sous système d'exploitation standard, une zone est réservée pour un accès au kernel, pour des raisons de performance. La zone fait donc entre 2 et 3 GB suivant le mapping choisi pour l'adressage (plus il y a de mémoire physique dans la machine, moins l'espace privé est grand, en bref).
Localisation et types de zones
A chaque instant, chaque processus a l'impression que cette mémoire est toujours entièrement accessible, chacune avec ses droits respectifs (code en lecture/exécution; données en lecture/écriture), quoique parfois lente. Une partie peut résider sur disque plutôt qu'en mémoire physique (swap et pagination de code), voire être partagée entre plusieurs processus (code, objets partagés, données en copy-on-write non encore modifiées par un processus fils p.ex.)En ce qui concerne le code, celui-ci est chargé et déchargé à la demande: l'exécution d'un programme consiste simplement au mapping du fichier exécutable et des objets partagés nécessaires dans l'espace mémoire du processus, à charge de l'exécution proprement dite de générer des fautes de pages, qui conduiront au chargement du code réellement exécuté.
Swapping et paging
L'ensemble de la mémoire mappée par tous les processus peut largement dépasser la mémoire physique réellement installée. Le dispositf matériel très rapide qui s'occupe de cette abstraction et de cette sécurité, des conversions entre adresse privée et adresse réelle, ou de l'exécution de fonctions kernel de rappatriement de données s'appelle le MMU (Memory Management Unit), il est indispensable à la plateforme et à l'OS standard -- des versions embarquées de l'OS standard existent pour des processeurs sans MMU.
Taille idéale
On retrouve fréquemment l'idée que la taille de la swap devrait être deux fois celle de la mémoire RAM physique. Initialement, Linux (le kernel) n'avait pas de besoins de ce type. C'étaient les *BSD qui proposaient cette règle de calcul, en raison de la manière dont fonctionnait la mémoire virtuelle sur ces systèmes.Cependant, tout a changé avec le kernel 2.4. Dès ce moment-là, le sous-système de gestion de la mémoire pouvait non seulement ralentir le système en cas de swap insuffisant (probablement en jettant des pages READ/EXECUTE, comme du `text' -- le code des programmes trop vite, de manière à augmenter le buffer cache, pages qui devront être relues des exécutables plus tard, ralentissant significativement la performance), mais aussi provoquer la mort d'un processus qui a trop alloué de mémoire -- ou un autre au hasard...
On conseille donc aujourd'hui également la règle swap = 2 x RAM sur un système GNU/Linux. Jusqu'à environ 2 GB,
disons.
Type de zones de swap
Linux reconnaît deux types de zones de swap, qui peuvent être déclarées dans /etc/fstab ou manuellement activées
et désactivées.
- les partitions de swap, usuellement de type 0x82, de taille jusqu'à 2 GB environ.
- les fichiers de swap, préalloués avec
dd if=/dev/zero of=mon_fichier_de_swap bs=1024k count=500, ici 500 MB, marqués avecmkswap mon_fichier_de_swapet activés avecswapon mon_fichier_de_swap.
Plusieurs zones de swap sont possibles et une priorité peut être définie. Il faut se rappeler cependant que chaque zone de swap diminuera, en cas d'utilisation effective, d'autant le MTBF du système (on peut le considérer comme du RAID 0 sur de la mémoire ...). D'où l'idée d'utiliser du swap par-dessus le RAID 1 (miroir).
La première partition de swap peut également être utilisée pour le save to disk des portables, si elle est de taille suffisante et du bon type.
Performance des zones de swap sur fichiers
Impact éventuel de la journalisation et du VFS
La plupart des fs journalisés ne journalisent que les métadatas (sauf une
option rarement utilisée de ext3), soit les structures de données du
système de fichiers. Le fichier de swap ne grossissant jamais
(taille définie une fois pour toute via dd avant mkswap; donc pas
d'extension de la liste des blocs du fichiers ou des pointeurs indirects), et les
modifications d'inode (méta-données) étant inexistante (même si noatime pas configuré)
dans ce cas précis (comme les fichiers mmap(2)és), à mon avis, la
journalisation n'a aucun impact dans ce cas, en particulier pas à l'usage.
Il y aura certes un peu de performance perdue à travers les couches du VFS, mais rien en comparaison avec le facteur 1'000? 10'000? de temps d'accès au disque-dur.
"Fragmentation", non-contiguité et fragmentation BSD/FFS
La fragmentation (sens Microsoft) c'est le fait que les blocs de données d'un fichier (et, sur UNIX, également les contenus des répertoires) soient non contigus. UNIX parle plutôt de "*non-contiguité*". Plus clair, plus simple, utilisez ce mot svp! C'est comme le mauvais mot formatage pour création de systèmes de fichiers; ou bien sûr le mot cluster utilisé pour tout et rien dire.
fsck.* reporte la "fragmentation" (sens Microsoft) comme "non contiguous", ce qui est plus clair.
ext3 évite la non-contiguité grâce à la préallocation de blocs de données (unique à Linux) et à
la répartition de données sur les groupes de cylindres (commun à BSD/FFS). Cette stratégie élimine complètement
la fragmentation sauf dans des cas particuliers (p.ex. remplissage du disque-dur à plus de 90% -- d'où la réserve
préconfigurée à la création du système de fichiers). Il y a un article de Roberto DI COSMO (la secrétaire efficace)  @@@ lien?
@@@ lien?
Originellement, le but d'augmenter la taille de bloc atomique du filesystem (p.ex. de 1k à 4k) était double:
- éviter de dépasser un numéro de bloc (LBA) dépassant la capacité de représentation interne (p.ex. 16 ou 32 bits) pour de grandes quantités de données
- augmenter la performance pure (throughput) des gros transferts
Microsoft a poussé cette stratégie de manière relativement stupide, avec des tailles de blocs (ce que Microsoft
appelle incorrectement un cluster ...) dépassant les 64k. Cela signifiait alors que créer 1'000 fichiers de 1 kilobyte
n'utiliserait pas 1 Mégabytes mais bien 1000 x 64k, soit 64 Mégabytes!
UNIX (BSD/FFS) a eu l'idée de fragmenter un bloc atomique du filesystem pour y placer plusieurs petits fichiers, augmentant ainsi l'efficacité de stockage des données, au prix d'une faible dégradation de performance éventuelle. ext3 ne supporte pas cette optimisation, mais comme la taille de bloc est assez faible (4k) et que les fichiers systèmes ont grossi avec le temps, avec les disques-dur, cela n'est plus autant critique.
Impact de la non-contiguité ("fragmentation")
Comme le fichier de swap est créé assez tôt ou lorsque le filesystem n'est pas encore rempli à plus de 90%, on peut supposer que la non-contiguité est inexistante, d'où aucun impact de la "fragmentation". En conséquence du fait que les méta-données ne changent pas aucune non-contiguité subséquente ne peut en résulter.
Par contre, il y aura de toute manière groupage par groupes de cylindres, ce que fait ext3 dès que la taille d'un fichier dépasse une certaine valeur. Vu le principe que `les données sont locales', cela ne devrait pas poser de problèmes particuliers.
Performance résultante du swap sous environnement standard
D'ailleurs le but d'un swap, sous Linux, n'est pas de s'en servir, mais d'en avoir en cas d'urgence, ou pour sauver des pages de données qui ne servent plus à rien depuis longtemps et dont la mémoire physique pourrait être à juste titre utilisée pour autre chose, comme du cache disque!Un swap actif est donc une très mauvaise chose.
Sécurité
Les données swappées finissant sur le disque-dur, cela pose un problème de sécurité assez grave si l'accès à la partition ou au fichier de swap n'est pas sécurisé. Les permissions UNIX s'appliquent bien sûr, et en général les valeurs par défaut de la distribution sont adéquates, au moins pour les partitions.
Par contre, on doit supposer que l'accès en dehors de l'OS reste possible à de vieilles données éventuellement migrées
dans le swap. Par exemple des clés privées de chiffrement GPG ou SSL, des mots de passe, etc. La solution POSIX est d'utiliser l'appel système mlock(2) sur les zones de mémoires concernées, bloquant celles-ci en mémoire physique. Comme cette
fonctionnalité peut être détournée de son objectif initial (déni de service, DoS?), elle est privilégiée. Cela signifie que les
programmes utilisateurs qui en font usage doivent obtenir ce privilège, par exemple via le mécanisme de SUID, ou les
capabilities si celles-si sont configurées dans le système. Dès le kernel 2.6.9 cependant, cet appel système n'est plus
privilégié, et des limites, via ulimit(2) et la commande interne du shell ulimit permet de configurer cela.
A voir, Ubuntu 6.06 LTS n'implémente aucune limite préconfigurée, ce qui à mon avis est un BUG, j'en ai informé Ubuntu (pas de manière stricte, cependant) le 2006-10-18:
Since 2.6.9, mlock(2) changed: now, every process is allowed to force pages to stay in physical memory, until the barrier set through ulimit(2) (or the bash internal command ulimit) are met. The previous behaviour was to allow mlock(2) only to root or properly capable processes (lcap(8)). This has an advantage: end-user programs no longer need a SUID root security risk (such as GPG; etc). However, at least on my version of Ubuntu (6.06 LTS), there is no preconfiguration for that item. I would set it to half of the system memory and document it somewhere. One can regret that the kernel developpers pass so heavy changes in a kind-of-stable release (I prefer to stick to 2.4 on servers or systems which need to be reliably managed myself for now), but it happened ... Where can I suggest changes to ulimit policies like this ?
L'autre utilisation (autre que la sécurité décrite ici) de mlock(2) est pour les applications à temps de réaction critique,
qui se combine souvent à la modification de la politique de scheduling à un scheduling temps réel, en dehors du round-robin
à temps partagé et quantas d'UNIX.
Une autre méthode d'assurer globalement la sécurité est d'écraser (dd if=/dev/zero of=/dev/hdaX) les données. Cela prend
beaucoup de temps à l'extinction de la machine et n'est pas sûr du point de vue de l'analyse forensique. L'alternative la plus
sûre quoique la plus lente est de passer via un loop device chiffré:
LODEV=`losetup -f` \
&& dd if=/dev/zero of=f bs=1024k count=100 \
&& losetup --nohashpass --pass-fd 3 3</dev/random -e des $LODEV f \
&& mkswap $LODEV \
&& swapon $LODEV
@@@ non testé. Il y-a-t-il mieux que des? 3des?
Différence entre mémoire allouée par malloc(3) ou brk(2) et mémoire accédée effectivement
L'allocation de mémoire sur les systèmes Linux `actuels' est assez simple: on dit ok, c'est bon (appel système brk(2)), tant que ce qui est demandé peut tenir dans l'espace mémoire privé du processus (de 2 à 3 GB suivant le mapping mémoire choisi: s'il y a plus de 1 GB de mémoire dans la machine, environ, disons 2 GB par processus sur plateforme standard pour simplifier).
La zone de mémoire allouée est simplement mmap(2)ée dans l'espace mémoire du processus, et un gestionnaire (handler) de faute de page spécifique y est associé, via le MMU. Cet handler est appelé en cas d'accès. En lecture, il générera des NULs (ASCII zéro), en écriture il allouera réellement la page et de désinstallera comme handler.
Cela ne signifie pas du tout qu'il y a assez de mémoire logique (RAM + swap), voire physique (RAM) pour allouer effectivement les données. Il y a comme pour les réservations de voyages en avion overbooking, ou overcommitting -- la pénalité de ce compromis est la mort pour le processus qui n'a pas eu de chance.
Comportement d'allocation réel
Cette allocation réelle peut provoquer:
- la diminution de la taille de la mémoire allouable atomiquement (non allouée), si l'on reste en-dessus des limites configurées dans
/proc/sys/vm/ - la diminution du cache disque en lecture (cached) ou déallocation de pages de programmes text, mais cela est choisi en dernier recours
- la suspension du processus (état S, voire D) s'il faut p.ex. aller écrire des pages du buffer-cache de manière à libérer de la mémoire, s'il faut swapper d'autres pages pour libérer de la mémoire physique
- et s'il n'y a pas de possibilité d'allouer une page: l'envoi d'un signal (car il est trop tard pour retourner une erreur p.ex. de
malloc(3)), voirkill -l, pour indiquer la condition plus de mémoire (Out of memory, OOM) au processus, signal qui peut être traité par le processus (ce que fait p.ex. OpenOffice), ou provoque la terminaison du processus (ainsi qu'un message dans le kernel log)
Exemple pratique en C et discussion
Un petit exemple:
/* Le programme ne fonctionnera peut-être pas comme prévu, tout dépend
* comment la libc gère l'allocation, je n'ai pas essayé récemment!
* A vos risques et périls.
*/
#include <stdlib.h>
#include <stdio.h>
int main(int argc, char **argv) {
unsigned long int bytes_allocated = 0;
unsigned char *addr;
while ((addr = malloc(4096))) {
bytes_allocated += 4096;
#ifdef TOUCH
addr[0] = 1; /* touch */
#endif /* TOUCH */
}
printf("allocated: %lu bytes.\n", bytes_allocated);
return 0;
}
En 2.4, ce programme devrait, si TOUCH n'est pas défini, allouer jusqu'à 2 ou 3 GB de mémoire (donc éventuellement plus que de mémoire physique installée) puis finir par une erreur (ENOMEM), par défaut: l'address space du processus a été totalement mangé, les tables MMU ont été allouées, mais personne n'a jamais réellement accédé aux pages concernées: elles n'ont pas été véritablement allouées.
Si l'on définit TOUCH, dans ce cas, ce programme va manger toute la mémoire libre, attaquer les caches, les buffers, déplacer en swap des données, jeter des pages de code, etc, puis il finira probablement par se faire tuer, ou malencontreusement tuer un gros processus autre (eh oui), voir dans certains rares cas causer d'autres problèmes, suivant le(s) processus touché(s).
Le problème est que l'allocation réelle de la page qui était de trop (la dernière bouchée, le dernier petit chocolat alors que les dents du fond baignent déjà) ne fonctionne pas.
Cette allocation réelle correspond en fait au premier accès en écriture à la page.
Mais le processus qui a voulu allouer une page n'est pas forcément celui qui a demandé beaucoup de mémoire. De plus, il est trop tard pour `retourner une erreur' ou autre: il faut envoyer un signal POSIX pour indiquer cette condition, qui peut être éventuellement traitée. Sinon, le processus est terminé.
The OOM Killer
Les premiers OOM-killer (Out Of memory killer) de Linux tuaient le processus qui demandait la page. Souvent, c'était le serveur X, et pas le méchant processus `mange-tout'. D'autres stratégies ont été développées, que l'on peut activer et désactiver par compilation du kernel. La stratégie pré-compilée par votre distribution prend en général une bonne décision pour les systèmes interactifs du moins (X11).Les motivations de l'overcommit et les améliorations possibles
Mais pourquoi, finalement, séparer l'allocation de mémoire de l'allocation réelle de la page ? La raison est simple: de nombreux programmes allouent beaucoup plus de place que nécessaire. Si l'on n'utilisait pas cette stratégie d'overcommit, il faudrait acheter beaucoup plus de mémoire/swap que réellement nécessaire, en particulier sur un serveur.Mais comment résoudre ce problème ?
- limiter les dégâts: certaines applications sont connues pour se planter magistralement en allouant toute la mémoire: il suffit alors de limiter la mémoire allouable ou allouée, en mémoire logique, voire mémoire physique, via
ulimit: cfulimit -a, via un wrapper de lancement de l'application: on peut aussi limiter globalement (et pas par application ou utilisateur/login) pour le système, ou faire le contraire (limiter et élever la limite pour certaines applications) - mettre plus de mémoire logique (plus de RAM, SWAP == 2 x RAM jusqu'à 2 GB de SWAP sur plateforme standard).
- supprimer l'overcommit (au moins partiellement)
Oui, il est possible de revenir à un comportement plus sain (ou du moins plus prévisible), mais plus dispendieux, de préallocation réelle des pages.
En 2.4 on cherche
find /proc -name '*overcomm*'
et on lit la manpage (man 5 proc) qui concerne cela.
Malheureusement -- à ma connaissance -- supprimer complètement l'overcommit est impossible en 2.4. On peut simplement donner des indications au système dans le sens voulu. En 2.4, on a donc intérêt d'ajouter également une stratégie reposant sur une limitation des dégâts.
Changements en kernel 2.6
En 2.6, il semblerait que l'on puisse définir des paramètres d'overcommit plus complexes, comme un pourcentage maximum.Je laisse des personnes plus expérimentées compléter pour cette nouvelle version.
Bon dimensionnement de la RAM
Une astuce pour bien dimensionner la mémoire sur un serveur standard:
- mettre 2 GB de swap
- laisser le système en fonction quelques jours
- regarder (
sar,vmstat 5dans un screen, etc) si le swap est actif en permanence ou souvent.
S'il y a des pages dans les swap, même beaucoup, style 200-500MB mais que ces pages ne sont jamais cherchées du swap (swap-in, si dans =vmstat 5=), ou ne sont jamais créées, sinon au début du fonctionnement du système, pas besoin de rajouter de la RAM.
En pratique
Redimensionnement d'un volume logique LVM
@@@ intégrer ma documentation texte/latex sur LVM (snapshots, etc) ici.Introduction
Vous avez été prévoyant: vous n'avez pas alloué toute la place disponible d'un groupe de volumes (volume group,vgdisplay -a) et vous allez pouvoir maintenant l'attribuer -- ou vous avez rajouté des volumes physiques, de préférence en RAIDx (x >= 1), ou encore vous avez réduit l'espace utilisé par un volume logique.
Vous allez pouvoir augmenter la taille d'un système de fichiers sans downtime ou avec un downtime minimal.
La diminution de taille n'est pas traitée ici (elle fonctionne de manière simple aussi avec e2fsadm).
Pré-requis
L'utilisation dee2fsadm demande:
- système de fichiers ext2 ou ext3 -- vous avez très peu de raison d'utiliser autre chose!
- utilitaires LVM version 10 -- la version plus récente nécessite une mise en oeuvre manuelle du redimensionnement, pour le moment
- l'utilitaire de redimensionnement resize2fs
ATTENTION: ne vous trompez pas de version de LVM à l'installation. Notamment, l'OS non standard Fedora Core 5 utilise par défaut une version trop récente de LVM, compatible dans une certaine mesure avec l'environnement standard, mais incompatible avec e2fsadm et non testé.
Principe de l'extension de capacité
e2fsadm va tout d'abord redimensionner le volume logique à la dimension demandée, puis redimensionner le système de fichiers via resize2fs. Pour ce faire, le système de fichiers doit être démonté -- et sera vérifié! Cela peut prendre un temps non négligeable.
Redimensionnement en-ligne
Avec des patches et l'utilitaire e2online, il est en théorie possible de redimensionner sans aucun downtime. Je n'ai pas testé cet outil récemment. De plus, il nécessite des patches kernel et la création du système de fichiers de manière spécifique.
EVMS
EVMS est une extension plus moderne basée sur LVM20 qui permet une gestion plus simple des volumes logiques, et des opérations plus avancées. Mon expérience avec cet outil est pour le moment très limitée!
Synchronisation de données
Introduction
Le but de cet article est de présenter de manière générale la synchronisation de données et de présenter des cas pratiques où l'on peut la mettre en oeuvre.
Définitions et applications
La synchronisation de données peut servir dans plusieurs cas distincts
- sauvegarde différentielle (p.ex. site distant)
- systèmes redondants (haute fiabilité) maître/esclave p.ex.
- systèmes à haute performance (redondance des données, en lecture seulement ou même en lecture/écriture; problème hautement complexe)
- travail déconnecté (p.ex. deux laptops employés alternativement)
La synchronisation peut s'appliquer sur différents objets:
- fichiers, systèmes de fichiers
- block-device
- base de données: ligne, table, base de données ou serveur entier (avec cohérence transactionnelle répartie)
- ensemble cohérent d'un système de contrôle de version
La synchronisation de données peut être implémentée de différentes manières, suivant la granularité de synchronisation (délai, contrôle de version éventuel, etc)
- contrôle de version (CVS, RCS, Subversion) (eh oui!)
- la méthode idéale pour les groupes de travail, la sauvegarde cohérente automatisée et la synchronisation en mode déconnecté
- système de fichiers à mode déconnecté (Coda, InterMezzo?, etc)
- utilisable pour des données moins cohérentes que celles gérées dans un CVS
- RAID1 par réseau (drdb)
- principalement pour la haute fiabilité (résistance au panne) en mode master/slave
ou, plus simplement:
- synchronisation régulière par logiciel en user-space
- rsync, unison, etc
Cas particulier: deux portables
Présentation du problème
Deux portables de matériel différent, de configuration parfois légèrement différentes, sont à synchroniser: ils sont en effet utilisés alternativement. On ne désire pas que synchroniser les données (ce qui serait bien plus simple), mais également le système (mises à jour de sécurité, configuration, etc).Il n'y a pas besoin ici de contrôle de version ou de gestion de conflits, vu que les portables ne sont pas utilisés en même temps. S'ils le sont, l'utilisateur est responsable d'éviter les problèmes manuellement (p.ex. en ne consultant pas les mails sur les deux portables, ou en utilisant p.ex. IMAP, et en acceptant que le système ou les données modifiées d'un des portables soient écrasés par l'autre).
Il peut y avoir des données qui ne sont pas communes, elles seront exclues de la synchronisation.
Choix de la technologie
On utilisera un système simple basé sur une synchronisation de donnéesrsync. Le principe est que rsync va
transférer uniquement les données qui ont changé, à chaque lancement de la commande. On devra choisir dans quelle
direction le transfert doit se faire.
Pour simplifier, le principe ici sera que c'est celui qui lance la commande de synchronisation qui sera écrasé par l'autre machine. Il faut donc utiliser les deux laptops en même temps le temps de la synchronisation, faite de préférence en console texte.
On n'utilisera pas rsync directement, mais un package d'abstraction CRIL.
Mise en place
Installation standard
voyager# apt-get install simple-data-rsync
Configuration
Prendre un exemple de configuration, et le modifier:
voyager# cp /usr/share/doc/simple-data-rsync/etc-backups-rotate.conf.sample /etc/backups-rotate.conf.VOYAGER voyager# chmod 444 /etc/backups-rotate.conf.VOYAGER voyager# vi etc/backups-rotate.conf.VOYAGER
Une partie de la modification consiste à indiquer le répertoire (qui sera /, ici il ne s'agit pas d'une sauvegarde incrémentale, le
cas typique de mise en oeuvre de simple-data-rsync).
Optionnellement, un script permettant de lancer l'opération de manière simplifiée:
voyager# cat > /root/scripts/rsync_reliant.sh <<EOF #! /bin/sh /usr/lib/simple-data-rsync/scripts/backup_rsync.sh reliant 10800 /etc/backups-rotate.conf.VOYAGER EOF voyager# chmod 700 /root/scripts/rsync_reliant.sh
Faire de même symétriquement sur la deuxième machine reliant.
Exclusion
Nous avons mentionné qu'il faut exclure certains fichiers. Les candidats sont:
-
/etc/X11/XF86Configou/etc/X11/xorg.conf -
/etc/hosts,/etc/hostname, voire/etc/mailname -
/etc/modules -
/boot/grub/menu.lstet éventuellement les images kernel si elles sont différentes (alors attention aux mises à jour de sécurité qui ne seront plus automatiquement synchronisées!)
Il suffit d'adapter le fichier /etc/backups-rotate.conf.VOYAGER et de configurer la variable
ADDITIONAL_EXCLUDES (séparer les noms de fichiers ou de répertoire par des /, ne pas
utiliser de métacaractères).
Synchronisation
Ensuite, synchroniser voyager à reliant ainsi:
voyager# /root/scripts/rsync_reliant.sh
Test
On peut utiliser la fonction md5sum (par exemple du package simple-scripts), ou carrément le package
simple-data-sync (sans le r!) pour comparer également les non fichiers et les permissions UNIX.
Autres solutions
Une solution qui peut, dans une certaine mesure, gérer les conflits est le logiciel unison. L'autre possibilité -- si on se
bornait aux données utilisateurs et éventuellement aux configurations systèmes -- serait le contrôle de version. On s'assurerait
alors que le jeu de données, lorsqu'on quitte un portable, serait =commit=té sur un serveur CVS.
Cas particulier: système master/slave
Introduction
Il s'agit ici de synchroniser un système esclave à un système maître de manière fiable, dans le but d'un failover éventuel. La problématique est un peu différente de celle des laptops, même si les outils sont similaires.
Il ne s'agit pas ici de load-balancing, mais bien de master-slave, ou fail-over.
Concept
Le système esclave tourne un système normal, mais avec la plupart des services désactivés, saufssh
et ntp. Pour ce faire, une modification des scripts de démarrage doit être effectuée.
On y lancera régulièrement à distance une procédure de synchronisation, du maître, via cron, avec un délai
maximum (timeout). Cette synchronisation exclut quelques fichiers, qui sont copiés spécialement (en zone d'attente).
Un mail sera envoyé si le système esclave ne fonctionne plus.
En cas de panne du serveur principal, le serveur principal (maître) doit être arrêté manuellement. Le serveur esclave est activé comme maître (manuellement, en activant quelques fichiers de configuration), notamment en reprenant son adresse IP.
Une sauvegarde réelle est faite de manière différente à ce qui est décrit ici.
Installation
On installe le package fail-over-support ainsi que les packages recommandés de synchronisation. Suivre
/usr/share/doc/fail-over-support/README.
Problèmes de la solution et idées d'améliorations
- sur le basculement
- pas de prise d'adresse MAC (c'est faisable, cependant; ou derrière routeur double)
- pas de voie de communication dédiée (faisable)
- pas de basculement automatisé (faisable)
- tuage électrique (prise télécommandée)
- sur la surveillance
- pas de surveillance étendue de services ou d'applications du maître par l'esclave
- intégrité des données
- pas de support particulier pour les fichiers qui changent sans changer le mtime
- p.ex. fichiers DB/DBM (annuaires de Samba en mmap(2))
- pas de support particulier pour les bases de données
- idéalement, le rsync devrait être fait avec les DB arrêtées
- ou le basculement fait après une restauration du dernier backup de qualité (dump, p.ex. psql8-backup)
- les données de l'esclave sont un snapshot non cohérent
- on pourrait faire le rsync d'un snapshot LVM
- les données de l'esclave datent, rsync est très lent si beaucoup de fichiers
- utiliser un RAID1 réseau, p.ex. ENDB ou DRDB
- pas de support particulier pour les fichiers qui changent sans changer le mtime
Types de machines virtuelles
Introduction
Le but de ce cours document est de donner quelques pistes pour une classification des machines virtuelles. Attention, ma façon de voir inclut des virtualisations qui n'en sont pas au sens strict usuel, mais qui ont certaines fonctionnalités.Dans ce qui suit le terme hébergé réfère à la machine virtuelle et hôte au système englobant.
Une description plus complète peut être lue à l'URL http://fr.wikipedia.org/wiki/Virtualisation
Fonctionnalités d'une machine virtuelle
Voici quelques fonctionnalités, qui sont ou non présentes
- émulation du processeur
- avantage: cela signifie que le processeur hébergé peut être différent du processeur hôte
- en conséquence une émulation du jeu d'instruction est nécessaire
- par interprétation du code binaire du processeur: qemu (sans kqemu)
- cas particulier: transcodage/morphing avec cache, similairement à ce que fait Transmeta
- par traduction préalable du code: propriétaire DEC Alpha fx32
- par transcodage par le matériel (PAL p.ex.): processeur Dec Alpha
- par interprétation du code binaire du processeur: qemu (sans kqemu)
- inconvénient: il y a normalement baisse sensible de performance (facteur 2 à 10)
- si le processeur est identique, on peut dans certains cas limiter grandement voire supprimer l'émulation (voir plus bas)
- émulation du matériel
- p.ex. le système hôte présente une couche logicielle vue comme matériel par l'hébergé
- carte réseau virtuelle relié à localhost ou VPN
- bus USB virtuel, relié au système USB réel filtré éventuellement
- BIOS virtuel, I/O virtuels: système entièrement virtualisé: bochs, c64emu
- avantages: virtualisation du matériel (pas besoin de pilotes dépendant du matériel, on peut donc bouger la VM facilement), sécurité (pas d'accès réel direct au matériel)
- inconvénients: perte de performance, quoique souvent négligeable sauf cas particulier
- p.ex. le système hôte présente une couche logicielle vue comme matériel par l'hébergé
- bibliothèques d'abstraction
- le système hébergé fait consciemment appel à une bibliothèque de virtualisation
- avantage: meilleure performance et flexibilité qu'en émulation matériel
- inconvénient: nécessite modification/recompilation du kernel hébergé; voire dans le cas Microsoft Windows une réimplémentation des bibliothèques, menant parfois à des problèmes de compatibilité
- exemples: UML, WINE
- mise à disposition directe du matériel
- certains matériels dédiés sont rendus accessibles directement par le système hébergé
- avantages: compatibilité même si le système hôte ne supporte pas le matériel; performance
- inconvénients: pas de partage de ressource, sécurité, pas de déplacement facilité de la machine virtuel sur un autre hôte sans le matériel considéré
- exemple: UML, qemu, virtualbox, xen, propriétaire VMware
- virtualisation du processeur
- le principe ici est que le système hébergé fonctionne à pleine vitesse dans le processeur de l'hôte, mais en mode non privilégié. Toute utilisation d'instruction privilégiée ou accès à du matériel non mis en disposition directe provoque un traitement dans le système hôte.
- avantage: pleine performance à part pour quelques instructions du système d'exploitation hébergé
- inconvénient: processeur doit être identique et virtualisable
- suivant le système d'exploitation et son utilisation d'instructions privilégiées ainsi que d'implémentations partielles de la virtualisation, il faudra un processeur particulier.
- exemples
- qemu avec kqemu (avec quelques problèmes suivant l'OS propriétaire, aucun avec GNU/Linux),
- Xen sur Intel récent (avec paravirtualisation) permet d'allouer un des deux processeurs d'un dualcore à un système hébergé, même un système propriétaire Microsoft Windows.
Cas particuliers
- chroot ou VLS
- il s'agit ici d'une simple isolation user-space.
- le kernel, le matériel et le processeur restent le même
- VLS ajoute à chroot
- le réseau peut être partiellement virtualisé
- chaque machine virtuelle a son propre espace de processus séparé
- dans les versions avancées un contrôle de la répartition CPU ou mémoire est possible * très performant, mais peu virtualisé
- user-mode-linux (UML)
- kernel modifié Linux qui sait qu'il est hébergé, tournant comme un seul processus du système hôte
- le processeur reste le même
- matériel accédé via une bibliothèque d'abstraction sur le système hôte (virtualisation complète du matériel)
- solution moins performante
- QEMU en mode émulateur
- processeur et matériel totalement émulés
- on peut faire tourner un Linux/i386 sur un Mac/PPC
- performance très mauvaise
- excellente isolation et virtualisation
- QEMU en mode kqemu
- matériel émulé
- processeur en exécution quasi-directe (interception des instructions privilégiées)
- performance bien meilleure que le cas émulateur, avec une moins bonne isolation et risque d'incompatibilités
Mise en garde
Même si ce document cite le GULL, je ne suis plus membre de cette association ni ne soutiens la manière dont elle est gérée.